前言
本节是有关指针内容的最后一节,本节的内容以讲解指针习题为主,那么就让我们一起来开启本节的学习吧!

sizeof和strlen的对比
1.sizeof
我们在学习操作符的时候,学习了sizeof。sizeof存在的意义是用来计算变量所占用的内存空间的大小的。sizeof的单位是字节,sizeof是一个单目操作符,不是一个函数
如果sizeof操作符的操作数是类型的话,计算出来的结果是使用该类型创建的变量所占空间的大小
int main()
{
int a = 10;
printf("%d\n", sizeof(a));
printf("%d\n", sizeof a);
printf("%d\n", sizeof(int));
return 0;
}
sizeof 操作符只关注操作数占用内存空间的大小,并不在乎内存中放的是什么数据
sizeof操作符的返回值最好用%zd来打印
sizeof因为是一个操作符,所以操作数要是一个变量的话,可以省略括号;这一点也间接地证明了sizeof不是一个函数
2.strlen
strlen是C语言的库函数,其功能是求字符串的长度
size_t strlen ( const char* str );strlen函数的本质是统计一个字符串从str这个地址开始向后,一直到 \0 之前的字符个数;
strlen函数仅仅针对字符串求字符串长度;
strlen函数的使用需要包含头文件<srting.h>;
int main()
{
char arr1[3] = { 'a', 'b', 'c' };
char arr2[] = "abc";
printf("%d\n", strlen(arr1));
printf("%d\n", strlen(arr2));
printf("%d\n", sizeof(arr1));
printf("%d\n", sizeof(arr1));
return 0;
}
注意:strlen函数会一直向后查找直到找到 \0 才会停止,所以可能会存在越界访问的问题
3.对比
1.sizeof是一个操作符,而strlen是一个库函数,strlen使用需要包含头文件<string.h>
2.sizeof计算操作数所占用内存的大小的,单位是字节;strlen是求字符串长度的,统计的是 \0 之前字符的个数
3.sizeof操作符不关注内存中存放的是什么数据;strlen函数关注内存中 \0 的位置,可能会存在越界访问的问题
有关数组和指针笔试题
一维数组
我们先来看一个笔试题:
int main(void)
{
int a[] = { 1,2,3,4 };
printf("%d\n", sizeof(a)); //1
printf("%d\n", sizeof(a + 0)); //2
printf("%d\n", sizeof(*a)); //3
printf("%d\n", sizeof(a + 1)); //4
printf("%d\n", sizeof(a[1])); //5
printf("%d\n", sizeof(&a)); //6
printf("%d\n", sizeof(*&a)); //7
printf("%d\n", sizeof(&a + 1)); //8
printf("%d\n", sizeof(&a[0])); //9
printf("%d\n", sizeof(&a[0] + 1)); //10
return 0;
}我们可以看到a数组中存放了4个整型元素,所以该数组是一个整型数组;
我们知道通常情况下数组名是数组首元素的地址,但是有两个特殊情况:
1.sizeof(数组名)——表示整个数组,计算的是整个数组的大小,单位是字节
2.&+数组名——数组名表示整个数组,取出的是整个数组的地址
1号代码:
因为数组里面有4个元素,每个元素的类型都是int,int类型占用4个字节,所以我们打印出来的值应该是16
2号代码:
代码2中,(数组名+0) 并不是一个单独的数组名,那么此时表示的就不是整个数组,那么此时的(数组名+0)表示的就是首元素的地址,所以打印出来的值应该是4(32位下)
3号代码:
我们可以知道a不符合两种特殊情况,所以此时的a就是首元素的地址,*a就是首元素,因为元素类型都是int,所以打印出来的值应该是4
4号代码:
我们知道sizeof(a+1)中的a是数组首元素的地址,因为+1跳过1个整型,所以a+1是第二个元素的地址,所以打印出来的值应该是4(32位下)
5号代码:
a[1]表示的就是第二个元素,所以它的大小就是4个字节
6号代码:
sizeof(&a)中&a是数组的地址,数组的地址也是一个地址,只要是地址它的大小就是4个字节(32位下),数组的地址和首元素的地址只在类型上存在差别,数组的地址为int (*) [4],首元素地址的类型为int *,类型的差异仅仅决定了+-操作跳过几个地址,因为它们都是指针,所以他们的值都是一样的
7号代码:
*和&符号相互抵消,该代码等价于sizeof(a),因为sizeof(a)是16个字节,所以该代码打印出来的值也是16个字节
8号地址:
&a+1跳过了整个数组,指向了数值最后一个元素的下一个元素,因为指针只是指向了最后一个元素的下一个元素,并没有解引用,所以不存在指针的越界访问。因为&a+1表示的仍然是一个指针,所以打印出来的值应该是4(32位下)
9号地址:
&a[0]表示取出数组首元素的地址,所以打印出来的值应该是4(32位)
10号代码:
&a[0]+1表示数组第二个元素的地址,所以打印出来的值应该是4(32位)

字符数组
第一题
int main(void)
{
char arr[] = { 'a','b','c','d','e','f' };
printf("%d\n", sizeof(arr)); //1
printf("%d\n", sizeof(arr + 0)); //2
printf("%d\n", sizeof(*arr)); //3
printf("%d\n", sizeof(arr[1])); //4
printf("%d\n", sizeof(&arr)); //5
printf("%d\n", sizeof(&arr + 1)); //6
printf("%d\n", sizeof(&arr[0] + 1));//7
return 0;
}我们在字符数组中放入了字符a,b,c,d,e,f
1号代码:
此时数组名单独放到了sizeof的内部,计算的是整个数组的大小,单位是字节,所以打印出来的值应该是6
2号代码:
arr+0 不满足两种特殊类型,所以arr表示的是首元素的地址,arr+0也是首元素的地址,所以打印出来的值应该是4(32位)
3号代码:
*arr表示对数组首元素的地址进行解引用,所以表示的是首元素,故大小为1个字节
4号代码:
arr[1]是第二个元素,大小是1个字节
5号代码:
&arr表示整个数组的地址,数组的地址也是一个地址,所以打印出来的值应该是4(32位)
6号代码:
&arr+1表示跳过整个数组,指向了数值最后一个元素的下一个元素的地址,所以打印出来的值应该是4(32位)
7号代码:
&arr[0]+1表示的是数组第二个元素的地址,所以打印出来的值应该是4(32位)
第二题
int main(void)
{
char arr[] = { 'a','b','c','d','e','f' };
printf("%d\n", strlen(arr)); //1
printf("%d\n", strlen(arr + 0)); //2
printf("%d\n", strlen(*arr)); //3
printf("%d\n", strlen(arr[1])); //4
printf("%d\n", strlen(&arr)); //5
printf("%d\n", strlen(&arr + 1)); //6
printf("%d\n", strlen(&arr[0] + 1));//7
return 0;
}1号代码:
此时的arr是首元素的地址,因为strlen在求长度的时候只有遇到 \0 才会结束,因为原数组中没有 \0 ,我们并不知道什么时候才会遇到 \0,就会导致越界访问,所以打印出来的值应该是一个随机值
2号代码:
arr+0表示数组首元素的地址,因为原数组中没有 \0 ,我们并不知道什么时候才会遇到 \0,就会导致越界访问,所以打印出来的值应该是一个随机值
3号代码:
*arr表示的是数组的首元素,就是'a'。因为strlen必须传入地址,因为字符a的ASCII码值是97,此时strlen函数就把97当作了一个地址,那么在打印时就会存在很多种情况:
1.打印出随机值
2.访问到了不允许访问的数据,程序崩溃
4号代码:
arr[1]表示的是第二个元素,就是'b'。因为strlen必须传入地址,因为字符b的ASCII码值是98,此时strlen函数就把98当作了一个地址,那么在打印时就会存在很多种情况:
1.打印出随机值
2.访问到了不允许访问的数据,程序崩溃
5号代码:
&arr表示取出整个数组的地址,数组的地址也是从数组的第一个元素的地址开始的,此时情况就和1号代码一模一样,打印出来的值应该是一个随机值
6号代码:
&arr+1指向了数值最后一个元素的下一个元素的地址,此时我们得到也是一个随机值,但是与1中的随机值存在差异(会比1号代码中的随机值少6,因为跳过了6个元素)
7号代码:
&arr[0]+1表示的是数组的第二个元素的地址,也就是从b开始向后统计的,打印出来的值应该是一个随机值(比1号代码中的随机值小1)
第三题
int main(void)
{
char arr[] = "abcdef";
printf("%d\n", sizeof(arr)); //1
printf("%d\n", sizeof(arr + 0)); //2
printf("%d\n", sizeof(*arr)); //3
printf("%d\n", sizeof(arr[1])); //4
printf("%d\n", sizeof(&arr)); //5
printf("%d\n", sizeof(&arr + 1)); //6
printf("%d\n", sizeof(&arr[0] + 1));//7
return 0;
}1号代码:
arr取出的是数组中所有的元素,所以打印出来的值应该是7
2号代码:
arr+0中的arr表示数组首元素,所以arr+0表示数组首元素的地址,所以打印出来的值应该是4(32位)
3号代码:
*arr表示的是数组的首元素,大小是一个字节
4号代码:
arr[1]表示的是第二个元素,大小为一个字节
5号代码:
&arr表示取出的是数组的地址,是地址就是4个字节(32位)
6号代码:
&arr+1表示跳过了整个数组,它还是一个地址,是地址就是4个字节(32位)
7号代码:
&arr[0]+1表示的是第二个元素的地址,其大小是4个字节(32位)
第四题
int main(void)
{
char arr[] = "abcdef";
printf("%d\n", strlen(arr)); //1
printf("%d\n", strlen(arr + 0)); //2
printf("%d\n", strlen(*arr)); //3
printf("%d\n", strlen(arr[1])); //4
printf("%d\n", strlen(&arr)); //5
printf("%d\n", strlen(&arr + 1)); //6
printf("%d\n", strlen(&arr[0] + 1));//7
return 0;
}1号代码:
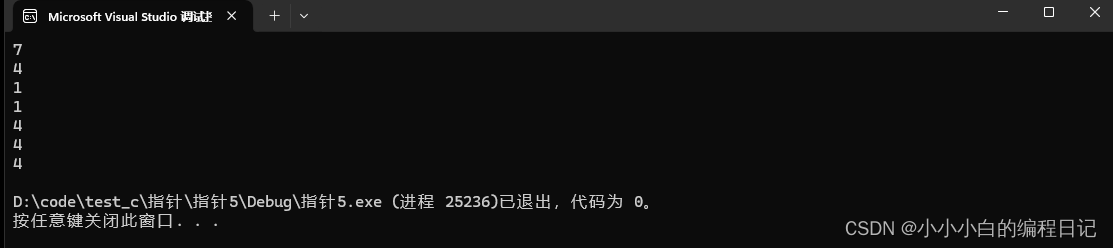
取出的是数组首元素地址,所以打印出来的值应该是6
2号代码:
取出的是数组首元素地址,所以打印出来的值应该是6
3号代码:
取出的是首元素'a',a的ASCII码值是97,此时strlen会把97当作一个地址,所以打印出来的值应该是一个随机值或者报错
4号代码:
取出来的是第二个元素'b',b的ASCII码值是98,此时strlen会把98当作一个地址,所以打印出来的值应该是一个随机值或者报错
5号代码:
取出来的是数组的地址,数组的地址也是首元素的地址,所以打印出来的值应该是6
6号代码:
此时+1跳过了整个数组,此时指向的就是数组最后一个元素的下一个元素的地址,所以打印出来的值应该是一个随机值
7号代码:
表示的是第二个元素的地址,所以打印出来的值应该是5
第五题
int main(void)
{
char* p = "abcdef";
printf("%d\n", sizeof(p)); //1
printf("%d\n", sizeof(p + 1)); //2
printf("%d\n", sizeof(*p)); //3
printf("%d\n", sizeof(p[0])); //4
printf("%d\n", sizeof(&p)); //5
printf("%d\n", sizeof(&p + 1)); //6
printf("%d\n", sizeof(&p[0] + 1)); //7
return 0;
}1号代码:
p是一个指针变量,是首元素的地址,我们计算的就是一个指针变量的大小,所以打印出来的值应该是4(32位)
2号代码:
是第二个元素的地址,所以打印出来的值应该是4(32位)
3号代码:
p的类型是char*,*p是char类型,所以打印出来的值应该是1
4号代码:
表示的是首元素'a',所以打印出来的值应该是1
5号代码:
表示的是一个二级指针变量,所以打印出来的值应该是4(32位)
6号代码:
表示的也是一个二级指针变量,&p+1表示的是跳过p指针变量后的地址,所以打印出来的值应该是4(32位)
7号代码:
表示的是数组第二个元素的地址,所以打印出来的值应该是4(32位)
第六题
int main(void)
{
char* p = "abcdef";
printf("%d\n", strlen(p)); //1
printf("%d\n", strlen(p + 1)); //2
printf("%d\n", strlen(*p)); //3
printf("%d\n", strlen(p[0])); //4
printf("%d\n", strlen(&p)); //5
printf("%d\n", strlen(&p + 1)); //6
printf("%d\n", strlen(&p[0] + 1)); //7
return 0;
}1号代码:
取出的是数组首元素的地址,所以打印出来的值应该是6
2号代码:
取出的是第二个元素的地址,所以打印出来的值应该是5
3号代码:
*p取出的是第一个元素,因为a的ASCII码值为97,strlen就会把97当作一个地址,所以打印出来的值应该是一个随机值或者报错
4号代码:
表示的是第一个元素,因为a的ASCII码值为97,strlen就会把97当作一个地址,所以打印出来的值应该是一个随机值或者报错
5号代码:
表示的是一个二级指针变量,所以打印出来的值应该是一个随机值
6号代码:
表示的也是一个二级指针变量,所以打印出来的值应该是一个随机值
7号代码:
表示的是第二个元素的地址,所以打印出来的值应该是5
二维数组
int main(void)
{
int a[3][4] = { 0 };
printf("%d\n", sizeof(a)); //1
printf("%d\n", sizeof(a[0][0])); //2
printf("%d\n", sizeof(a[0])); //3
printf("%d\n", sizeof(a[0] + 1)); //4
printf("%d\n", sizeof(*(a[0] + 1))); //5
printf("%d\n", sizeof(a + 1)); //6
printf("%d\n", sizeof(*(a + 1))); //7
printf("%d\n", sizeof(&a[0] + 1)); //8
printf("%d\n", sizeof(*(&a[0] + 1))); //9
printf("%d\n", sizeof(*a)); //10
printf("%d\n", sizeof(a[3])); //11
return 0;
}我们知道:该数组是一个三行四列的二维数组
1号代码:
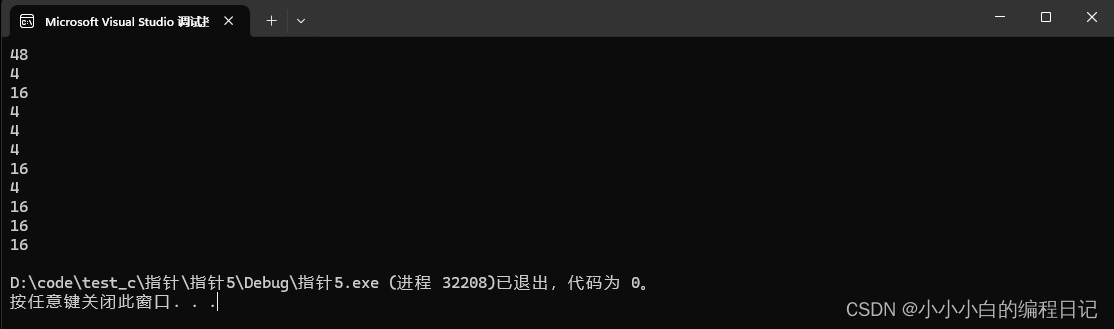
a是二维数组的数组名,所以表示的是数组的大小,所以打印出来的值应该是48
2号代码:
表示的是第一行的第一个元素,所以打印出来的值应该是4
3号代码:
表示的是第一行的所有元素,所以打印出来的值应该是16(a[0] 是第一行的数组名,数组名单独放到sizeof的内部,计算的就是第一行数组的总大小)
4号代码:
这种写法中,数组名并没有单独放到sizeof的内部,所以这里的数组名a[0]就是数组首元素的地址,就是a[0][0]的地址,+1后是a[0][1]的地址,所以打印出来的值应该是4(32位)
5号代码:
表示的是第一行的第二个元素,所以打印出来的值应该是4
6号代码:
a作为数组名并没有单独放到sizeof的内部,a表示的是数组首元素的地址,是二维数组的首元素的地址,也就是第一行的地址,+1跳过一行就是第二行的地址,是一个数组指针变量3,所以打印出来的值应该是4(32位)
7号代码:
表示的是a[1],表示第二行所有的元素,所以打印出来的值应该是16
8号代码:
a[0]是第一行的数组名,&a[0]取出的就是数组的地址,就是第一行的地址,所以+1就是第二行的地址,所以打印出来的值应该是4(32位)
9号代码:
表示的是a[1],表示第二行所有的元素,所以打印出来的值应该是16
10号代码:
a作为数组名并没有单独放到sizeof的内部,a表示的是数组首元素的地址,是二维数组的首元素的地址,也就是第一行的地址,*a就是第一行的所有元素,所以打印出来的值应该是16
11号代码:
a[3]表示的是第四行的数组名,因为sizeof并不会计算,也没有访问,所以不存在越界访问,所以打印出来的值应该是16,所以a[3]无需真实存在,仅仅通过类型的推断就能够算出长度
指针运算
题目1
int main()
{
int a[5] = { 1, 2, 3, 4, 5 };
int* ptr = (int*)(&a + 1);
printf("%d,%d", *(a + 1), *(ptr - 1));
return 0;
}我们来分析一下:
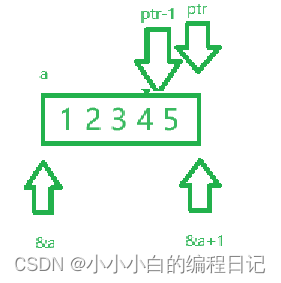
ptr-1指向的是数组的第五个元素,*(a+1)指向的是数组的第二个元素,所以打印出来的值是2和5

题目2
假设在 X86 环境下,结构体的大小是 20 个字节,那么程序输出的结构是什么?
struct Test
{
int Num;
char* pcName;
short sDate;
char cha[2];
short sBa[4];
}*p = (struct Test*)0x100000;
int main()
{
printf("%p\n", p + 0x1);
printf("%p\n", (unsigned long)p + 0x1);
printf("%p\n", (unsigned int*)p + 0x1);
return 0;
}这道题目考察的是指针+-整数的知识点
我们知道结构体指针+1会跳过一个结构体,所以+1就会跳过20个字节,所以 p+0x1 就表示0x100000 + 20 = 0x100014,因为打印的值是一个地址,所以要补满8位,所以打印出来的值应该是00100014
在(unsigned long)p + 0x1中,p被强制类型转换为unsigned long类型,此时p就不是一个指针变量了,所以此时整型值+1就是+1本身,所以打印出来的值应该是0x100001
在(unsigned int*)p + 0x1中,p被强制类型转换为unsigned int*类型,所以+1就会跳过4个字节,所以 p+0x1 就表示0x100000 + 4 = 0x100004,因为打印的值是一个地址,所以要补满8位,所以打印出来的值应该是00100004

题目3
int main()
{
int a[3][2] = { (0, 1), (2, 3), (4, 5) };
int *p;
p = a[0];
printf( "%d", p[0]);
return 0;
}注意第一行代码中的二维数组并不是如下的形式:
int a[3][2] = { {0, 1}, {2, 3}, {4, 5} };
它是用括号连接起来的,表示的是一个逗号表达式,逗号表达式从左向右依次计算,最后一个计算的值就是表达式的取值,所以数组的真实情况应该如下:
int a[3][2] = { 1,3,5 };因为数组是三行两列的,所以数据1 3 放到第一行,数据 5 放到第二行第一列,其他的三个位置上放的都是0
因为a[0]是第一行的数组名,数组名表示首元素的地址,其实就是&a[0][0]的地址
所以p[0] = *(p+0) = *p,所以打印出来的值应该是1

题目4
int main()
{
int a[5][5];
int(*p)[4];
p = a;
printf("%p,%d\n", &p[4][2] - &a[4][2], &p[4][2] - &a[4][2]);
return 0;
}我们首先创建了一个5行5列的数组,再创建了一个数组指针变量,p指向的是4个整型元素的地址
接着我们进行了&p[4][2] - &a[4][2], &p[4][2] - &a[4][2]两个操作,我们知道指针-指针得到的是两个指针之间的元素的个数
我们分析一下:a的类型是 int(*)[5],p的类型是 int(*)[4]
当我们把a赋予p的时候,两者的首地址都是指向a数组中的第一行的第一个元素,两者会有类型的差异,所以+-整数二者跳过的字节数不同
a每次+1跳过的是5个整型,而p每次+1跳过的是4个整型,我们画图分析如下:
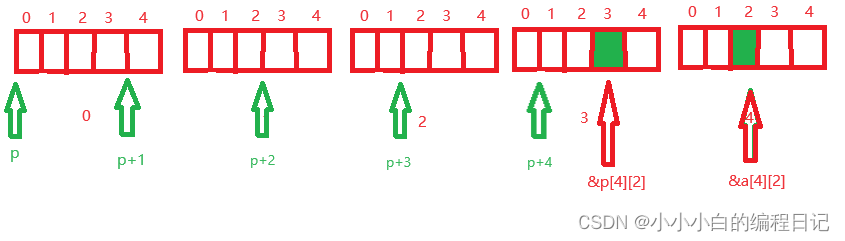
由图我们可以知道:两个指针相减得到的值是-4,所以%d打印出来的值就是-4;
而%p是打印地址,因为-4在内存中是以补码的形式存放的,-4的原码为:
10000000000000000000000000000100
所以-4的补码是:
111111111111111111111111111111111100
所以%p此时就把-4的补码当作一个地址打印出来了,我们把它的值换算成16进制,得到的是:
FFFFFFFC
所以打印出来的值就是FFFFFFFC和-4

题目5
int main()
{
int aa[2][5] = { 1, 2, 3, 4, 5, 6, 7, 8, 9, 10 };
int* ptr1 = (int*)(&aa + 1);
int* ptr2 = (int*)(*(aa + 1));
printf("%d,%d", *(ptr1 - 1), *(ptr2 - 1));
return 0;
}我们先来画图分析:
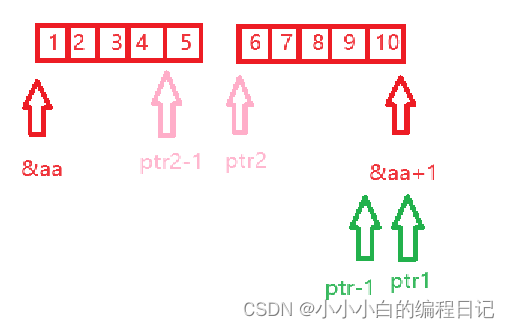
*(aa+1)等价于aa[1],aa[1]是第二行的数组名,因为数组名表示的是首元素的地址,所以aa[1]==&aa[1][0]
我们由图可知,打印出来的值分别是10和5

题目6
我们先画图分析一下:
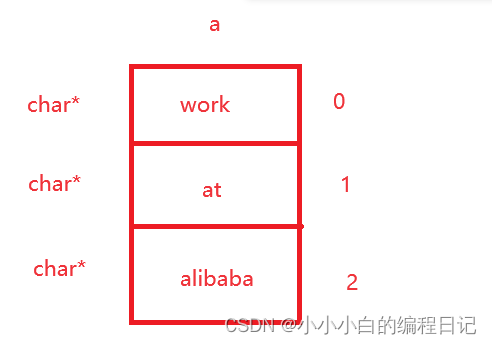
a是一个字符指针数组,数组里面一共有三个元素,数组的每个元素都是char*类型
因为二级指针变量pa被赋予了a,a是一个数组名,表示的就是首元素的地址
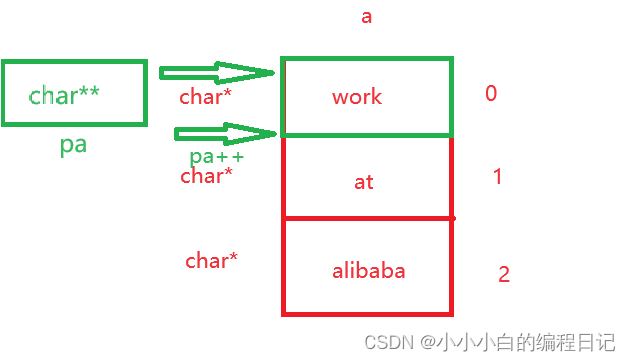
据图分析,我们可以知道打印出来的值是"at"

题目7
int main()
{
char* c[] = { "ENTER","NEW","POINT","FIRST" };
char** cp[] = { c + 3,c + 2,c + 1,c };
char*** cpp = cp;
printf("%s\n", **++cpp);
printf("%s\n", *-- * ++cpp + 3);
printf("%s\n", *cpp[-2] + 3);
printf("%s\n", cpp[-1][-1] + 1);
return 0;
}题目比较复杂,我们试着画出图像来分析一下:
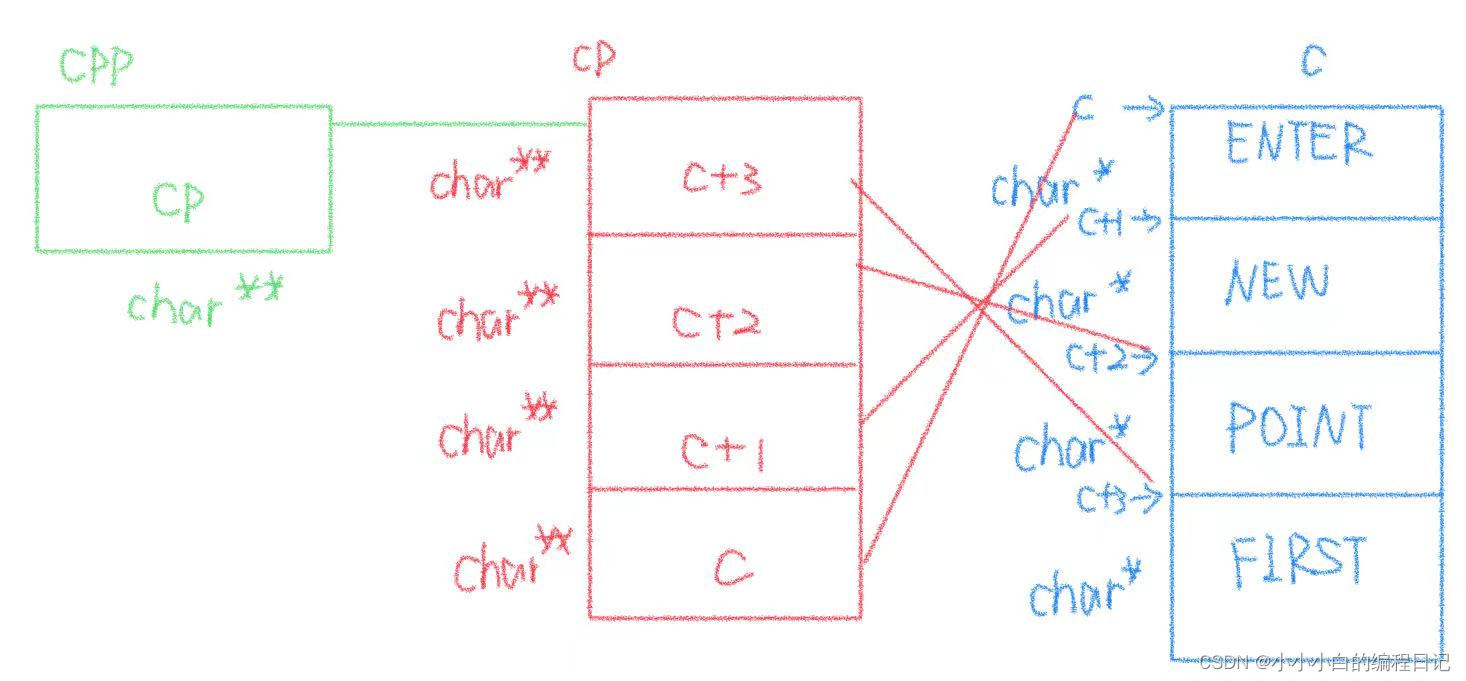
因为指针优先级的问题++cpp会率先进行,此时cpp的指向就会改变
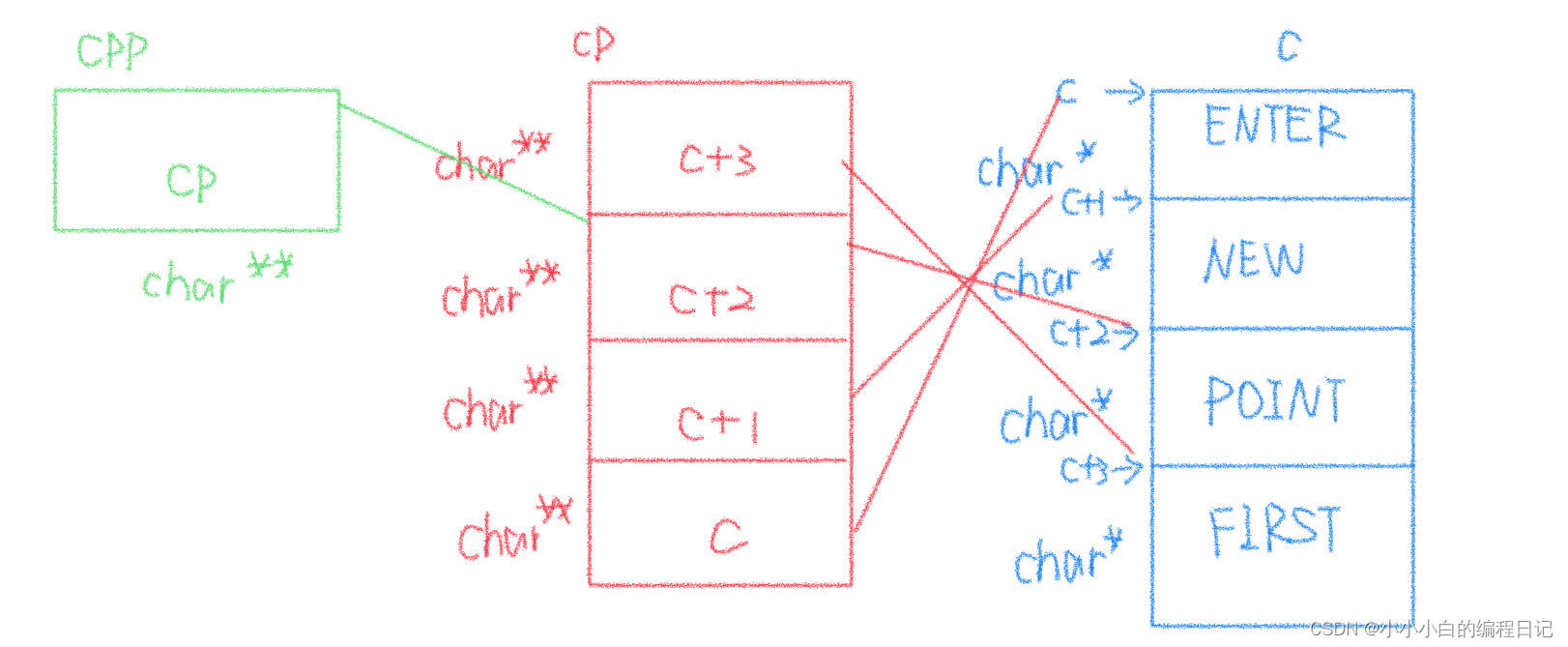
此时*++cpp拿到的值就是c+2,所以**++cpp表示的值就是*(c+2),此时打印出来的值就是"POINT"
接着来看第二个代码:* -- * ++ cpp + 3
我们知道这个代码中,+的优先级是最低的,我们应该先计算++cpp
因为上一个代码已经进行了++cpp的操作指向了c+2,此时在进行++操作指向的应该是c+1
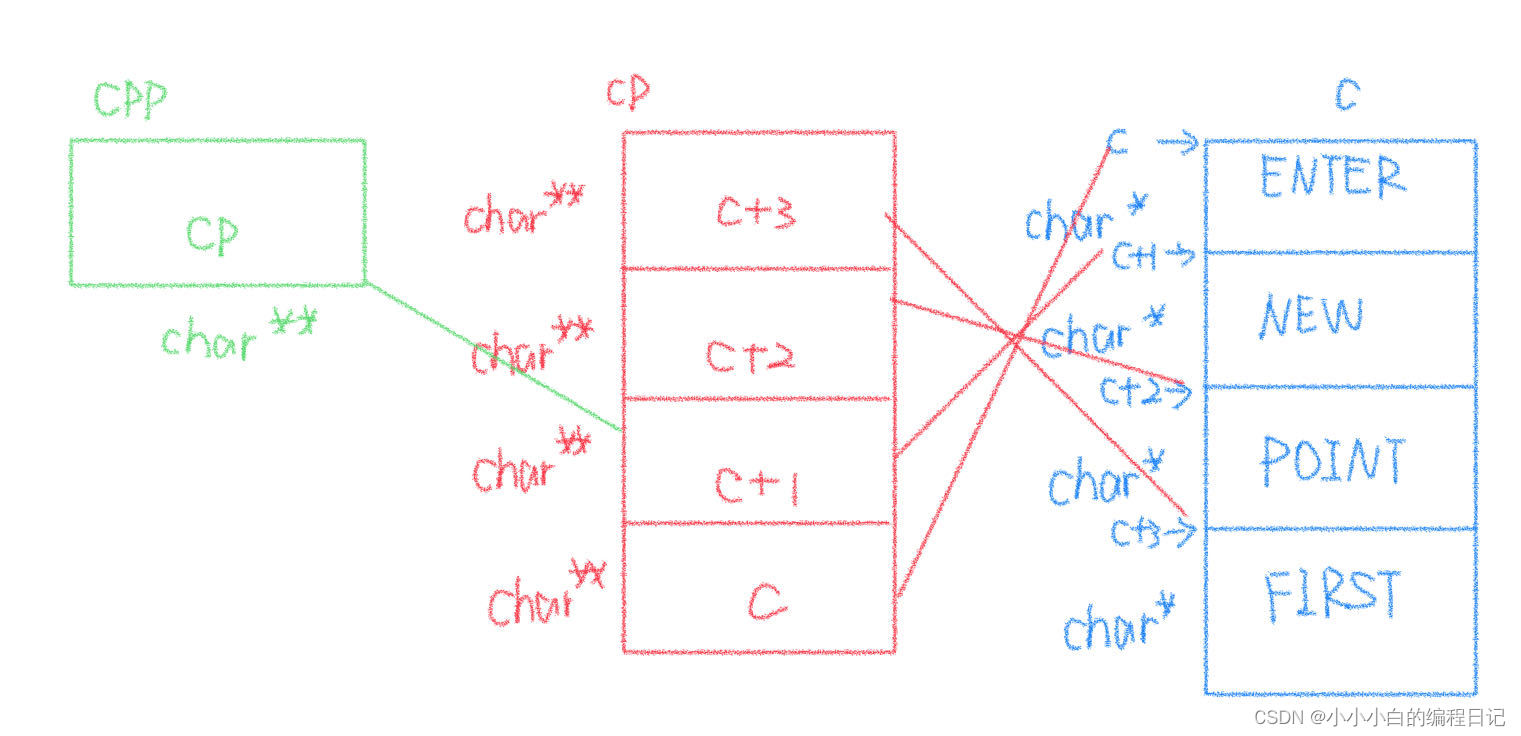
我们再依照优先级顺序进行解引用操作,此时拿到的是c+1,原代码就可以转化为*--(c+1)+3
接下来我们应该要执行--操作,因为--的对象是c+1,所以在执行完--操作以后,c+1的值会变成c

现在的原代码相当于*c+3,所以*c+3打印出来的值应该是"ER"
我们接着来看第三个代码:* cpp [-2] + 3
我们先把代码转换一下:* *(cpp-2) + 3
我们又应该先算(cpp-2),此时我们应该拿到的是c+3,我们再对(c+3)解引用拿到的是"FIRST"处的地址,再进行+3操作,所以打印出来的值应该是"ST"
我们最后来看第四个代码:cpp[-1][-1] + 1
我们再来把代码转换一下:*(*(cpp - 1) - 1) + 1
此时的逻辑和之前的代码一模一样,所以打印出来的值应该是"EW"

此题目中的重点就是++和--会改变取值,这就是我们之前所说的带有副作用的表达式
结尾
我们有关指针的所有内容到这里就结束了,希望这一系列的内容可以给你的学习带来帮助,谢谢您的浏览!!!